技术帝揭秘alphago为什么会下围棋,柯洁对战阿尔法狗必输的原因
最近谷歌的阿尔法狗又火爆了一把,因为他击败了目前世界排名第一的中国选手柯洁,很多人觉得非常的奇怪,机器是怎么下围棋的?围棋这样深奥的东西,难道不是人类最擅长的吗?而且柯洁跟阿尔法狗下完围棋后认为其水平已经接近围棋上帝的水平,很难被击败,下面转载一篇技术帝分析阿尔法狗是如何下围棋的!
技术帝揭秘alphago为什么会下围棋:
围棋的棋盘为 19x19 的网格,比国际象棋大,可能的下法(10^174)超过已知宇宙中所有原子数目的总和(10^80)。巨大的变数和可能性,让围棋棋道几乎成为一门玄学。
AlphaGo 下围棋的策略,与按人类预设剧本下棋的深蓝不同,其下棋算法没有经过人工调试,全部是靠自己学会的。
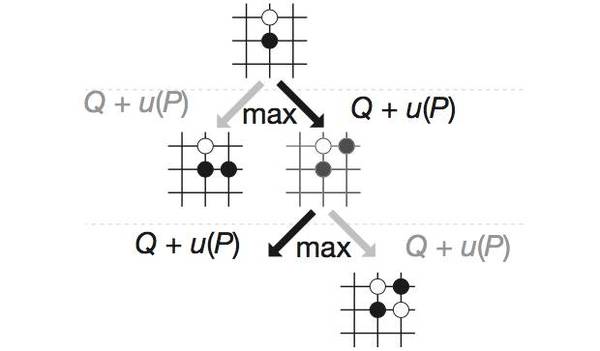
▍AlphaGo 的游戏树 / 图片来源:Nature
AlphaGo 怎么学?答案是人工神经网络。
人工神经网络是一种计算模型,可以在海量数据中找出规律。近年来,人工神经网络在人脸识别、机器翻译等领域被广泛应用。
▍与人类神经网络类似,人工神经网络的基本单位是神经元。一个神经元可以接收多个输入,在计算后可以产生一个输出。一个神经网络有若干层,每一层由成百上千个神经元组成。A:生物神经元,B:人工神经元(左侧箭头代表多个输入,右侧箭头代表一个产生的输出),C:突触,D:人工神经网络 / 图片来源:InTechOpen
AlphaGo 使用了两种人工神经网络,一个是预测网络(policy network),一个是评估网络(value network)。预测网络用来预测对手下一步可能怎么走,评估网络则用来评估给定棋局下己方的获胜概率。
人工神经网络要用海量数据训练。AlphaGo 输入了至少三千万种棋局,自我博弈超过一百万次。在与李世石对决前,AlphaGo 预测对手的准确率达到 57%超过半数的情况下,AlphaGo 能猜中对手下一步会怎么走 / 图片来源:Nature
相比深蓝,AlphaGo 采取的策略效率更高,战绩更辉煌。借助远胜于深蓝的计算能力和搜索策略,AlphaGo 搜索的深度与广度均大幅提高;深蓝要靠人工调试的算法才能战胜卡斯帕罗夫,AlphaGo 的下棋策略,却完全是靠自己在海量数据中摸索出来的。
柯洁对战阿尔法狗必输的原因:
理解了 AlphaGo 怎么下棋,就不难理解为什么柯洁必输。
首先,AlphaGo 的训练量、所见棋局和进步速度都远超柯洁。
AlphaGo 见过、下过的棋,以百万计。柯洁的训练量,我们做最乐观的粗略估算,也难以超过五万局。
根据启蒙老师李守胜的说法,柯洁可以说还在娘胎里的时候,就是听着围棋声长大的。我们假设 1997 年出生的柯洁,从负一岁就开始下棋,每天 24 小时不眠不休,每局 4 小时,在整整 21 年中,也只能下不到 5 万局。
需要指出的是,人类对棋谱的利用率远超人工智能。职业棋手通过几十局棋谱,就能大致摸清对手棋路。人工智能却需要至少数以万计的棋谱,才有可能发现其中规律。
而且,并非数据喂得越多,下棋水平越高。输入海量数据后,人工智能仍不得法的情况也很常见。
不过,一旦找到了规律,人工智能就进步神速。AlphaGo 只用两年,就从零起步登顶世界第一,手下败将包括李世石、聂卫平、柯洁。
本文转自搜狐网。